Tormes: Own Your Index - Part 1
Published on October 22, 2025 by h | 346 views
Since the end of internet as we know is approaching, gathering resources from it has become a key action that all users have to make. I won't use this post to explain this stance, but personally this has been a wake up call to me for starting downloading stuff that I consume or I think I will consume - media, other blogs' posts, webpages, etc. And yet there is a critical thing - in the era of AI what's gonna happen to search? What's gonna be the future of web indexing?
New products like Perplexity have arised to reinvent creatively how we use the web and providing a new for searching the internet by using natural language. Google on the other hand has added an AI Mode on the search results. This is the prelude of times that sign that we are closer to abandoning the soon-to-be old method which is or was visiting the web pages indexed on your search in order to get what you were looking for. Opinions aside, a critical question has to be formulated - what is going to happen the moment when search engines like Google Search are not profitable anymore? Where will the billions or trillions of indexed and cached webpages gonna end up? Will the Web remain the same or will we go into a new way of expression via LLMs? Or will the web become a training set for future LLMs or whatever is invented in the near future?

While we untangle these questions, I decided to build my own web indexer - Tormes.

The reason
I am developing Tormes because:
- I want to learn!!!!!: There's no better way to understand search engines than building one
- I wanna make niche searches!!!!: Sometimes you want to search only a specific corner of the web
- I wanna be careful!!!!: Because you never know when will they unplug the wire
The name "Tormes" comes from the Spanish picaresque novel Lazarillo de Tormes—a humble character with its own guide (Lazarillo).
The main use-case is research since it can help indexing topics of your interest through the web. This is useful if you are an organization and need to expand your knowledge on your field or if you are an AI researcher and need to elaborate specific training sets
Architecture
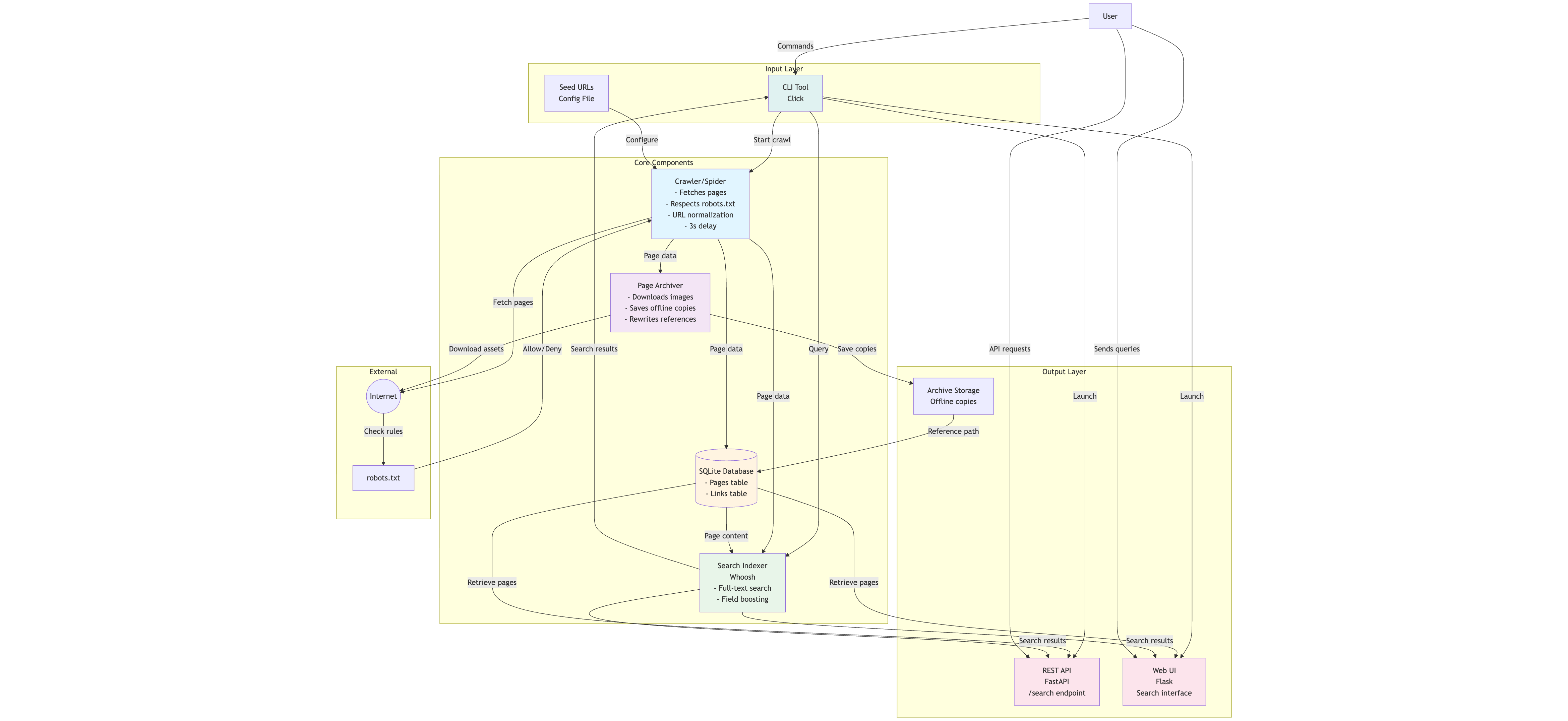
Any search engine consists of three main parts:
1. CRAWLER → Discovers and downloads web pages
2. INDEXER → Processes pages into searchable format
3. SEARCH → Retrieves relevant pages for queries
Plus a few supporting players:
- Storage (Can be SQLite database)
- Archiver (Although not all of them have them, it can be useful to save full offline copies)
- API (REST endpoints for search)
- Web UI (The visual face for searching)
This is how I built each piece of it.
1. The Crawler (Spider)
The crawler is the heart of the system. Its job is to start at seed URLs, fetch pages, extract links, repeat.
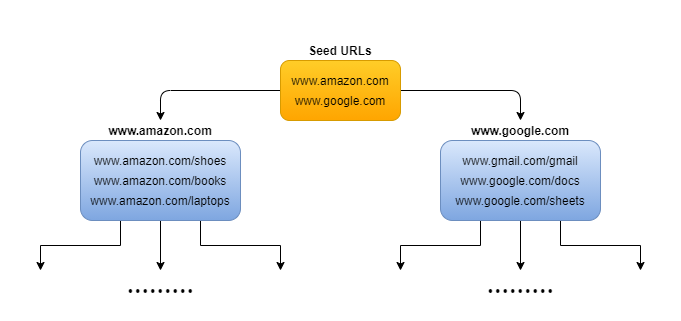
Starting Simple
Here's the core loop in pseudocode on a very very simple approach:
frontier = Queue()
frontier.add(seed_urls)
visited = set()
while frontier.has_urls():
url = frontier.get_next()
if url in visited:
continue
html = fetch(url)
visited.add(url)
links = extract_links(html)
for link in links:
frontier.add(link)
Key Decision: Single-Threaded
Most modern crawlers use async I/O or threading. Tormes doesn't. Why? Because of respect. We don't wanna DDOS or consume resources from an external server
By adding a time.sleep(3) between requests for example, you've got a respectful crawler that won't hammer anyone's server.
# In tormes/crawler/spider.py
time.sleep(self.config.get('crawler.delay_between_requests', 3.0))
How to respect robots.txt
This can be achieved using Python's built-in urllib.robotparser:
from urllib.robotparser import RobotFileParser
class RobotsHandler:
def can_fetch(self, url):
parser = RobotFileParser()
parser.set_url(f"{domain}/robots.txt")
parser.read()
return parser.can_fetch("TormesBot", url)
I'm storing them in the cache for an hour so Tormes doesn't deal with re-fetching.
URL Normalization
Anyone who has done a bit of crawler can face a situation in which there is URL canonization - e.g. two pages like example.com/page?b=2&a=1 and example.com/page?a=1&b=2 that lead to the same content in reality, but have different strings.
The most direct solution is to normalize before duplicate detection:
def _normalize_url(self, url):
parsed = urlparse(url)
# Lowercase domain
domain = parsed.netloc.lower()
# Sort query parameters
query = parse_qs(parsed.query)
sorted_query = urlencode(sorted(query.items()))
# Remove fragments
return f"{parsed.scheme}://{domain}{parsed.path}?{sorted_query}"
The URL Frontier
The frontier manages which URLs to crawl next. I used a simple FIFO queue (collections.deque) with domain-level tracking:
class URLFrontier:
def __init__(self):
self.queue = deque()
self.seen_hashes = set() # MD5 hashes for O(1) lookup
self.domain_counts = {} # Track pages per domain
This prevents one domain from dominating the crawl.
2. Storage (SQLite)
For the purpose of this project, in order to save the crawled content using just SQLite can be perfect for this — serverless, fast enough, and battle-tested.
Schema Design
Two main tables:
CREATE TABLE pages (
url TEXT PRIMARY KEY,
title TEXT,
description TEXT,
content TEXT, -- Extracted text
raw_html TEXT, -- Original HTML
archive_path TEXT, -- Path to offline copy
crawled_at TIMESTAMP
);
CREATE TABLE links (
source_url TEXT,
target_url TEXT,
anchor_text TEXT
);
The links table creates a graph of how pages connect—useful for future PageRank-style algorithms. This is will be a future addition that will rank each web page depending on how referenced is by other web pages (see: https://en.wikipedia.org/wiki/PageRank).
3. Full-Text Search (Whoosh)
As of right now, I have crawled of 1042 pages on my own Tormes instance. I could be using direct SQL queries with wildcards -for example, LIKE '%cats%'if I wanted to search for contents about kitties- but that will turn into a burden because they are super slow.
For this matter, the Woosh library can be useful and supplies our needs for full-text search.
Index Schema
from whoosh.fields import Schema, TEXT, ID, DATETIME
schema = Schema(
url=ID(stored=True, unique=True),
title=TEXT(stored=True, field_boost=2.0), # Titles more important
description=TEXT(stored=True, field_boost=1.5),
content=TEXT(stored=True)
)
Notice the field_boost—matches in titles count more than in body text.
Indexing a Page
When the crawler finishes a page, we will index it:
writer = index.writer()
writer.add_document(
url=page_url,
title=page_title,
description=page_description,
content=page_text
)
writer.commit()
Searching
Whoosh by itself can handle all the hard stuff (tokenization, ranking, etc.):
from whoosh.qparser import MultifieldParser
parser = MultifieldParser(["title", "description", "content"], schema)
query = parser.parse(query_string)
results = searcher.search(query, limit=20)
4. Page Archiving
I thought that archiving can fulfill the preservation stuff so adding a logic to save complete offline copies can be pretty interesting for that matter.
Why Archive?
- Pages change or disappear
- Offline browsing
- Historical snapshots
The Process
For each crawled page:
- Download the HTML
- Parse it to find all images
- Download each image
- Rewrite HTML to reference local copies
- Save everything to disk
Image Download Strategy
def _download_images(self, soup, base_url, archive_dir):
assets_dir = archive_dir / 'assets'
assets_dir.mkdir(exist_ok=True)
failures = 0
for img in soup.find_all('img'):
src = img.get('src')
if not src:
continue
try:
img_url = urljoin(base_url, src)
img_data = self._fetch_asset(img_url)
# Use content hash for deduplication
content_hash = hashlib.md5(img_data).hexdigest()
filename = f"{content_hash}.{extension}"
# Save and rewrite reference
(assets_dir / filename).write_bytes(img_data)
img['src'] = f'assets/{filename}'
except Exception as e:
failures += 1
if failures >= self.max_image_failures:
break # Don't hang on broken images
Failure Threshold
I noticed that sometimes the archiver can get stuck on an infinite loop if it is not able to download images from a website. For this, there is a threshold of 3 attempts - after that it will skip the download.
5. Configuration
Hard-coding settings is brittle and the whole point is to make it as customizable as possible. Tormes loads a YAML config file at the beginning with the following format (summarized):
crawler:
delay_between_requests: 3.0
max_pages_per_domain: 100
respect_robots_txt: true
seed_urls:
- https://example.com
topic_filters:
keywords: ["python", "programming"]
storage:
database_path: data/tormes.db
archive_path: data/archive
archiver:
max_asset_size_mb: 5
max_image_failures: 3
My plan before the first release is to add a bunch of config files depending on topics or the level of crawling someone could want.
6. The API (FastAPI)
I have positive experiences with FastAPI and I think nowadays it is a standard. Tormes handles API requests completely:
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class SearchRequest(BaseModel):
query: str
limit: int = 10
page: int = 1
@app.post("/search")
def search(request: SearchRequest):
results = search_index.search(
request.query,
limit=request.limit,
page=request.page
)
return {"results": results}
Auto-generated docs at /docs. Beautiful.
7. The Web UI (Flask)
To give a more interactive feel, Tormes has a web UI based on Flask but it is only for searching through your index. I took the freedom of applying the same aesthetic as Erratia:
from flask import Flask, render_template, request
app = Flask(__name__)
@app.route('/')
def index():
query = request.args.get('q', '')
if not query:
return render_template('search.html')
results = search_index.search(query)
return render_template('results.html', results=results)
Templates use Jinja2 for highlighting search terms, showing snippets, etc.
8. The CLI Tool (Click)
This is the core of Tormes and where it starts the searching, crawling and indexing. Everything is tied altogether with a command-line interface:
import click
@click.group()
def cli():
pass
@cli.command()
@click.option('--max-pages', default=100)
def crawl(max_pages):
spider = Spider(config)
spider.crawl(max_pages=max_pages)
@cli.command()
def serve_api():
uvicorn.run(api.app, host='0.0.0.0', port=8000)
if __name__ == '__main__':
cli()
Usage:
# Crawls 100 pages
python -m tormes.cli crawl --max-pages 100
# Search for Python tutorials
python -m tormes.cli search "python tutorials"
# Serve the API
python -m tormes.cli serve-api
# See the stats
python -m tormes.cli stats
Key Lessons Learned
1. Callbacks > Return Values
The crawler uses a callback pattern:
def on_page_crawled(page_data):
storage.save_page(page_data)
search_index.index_page(page_data)
archiver.archive_page(page_data)
spider.on_page_crawled = on_page_crawled
spider.crawl()
This decouples the crawler from storage/indexing. The crawler doesn't care what you do with pages — it just notifies you.
2. Normalize Early
Normalize URLs before duplicate detection, not after. Otherwise the same page will be crawled multiple times.
3. Fail Gracefully
Networks are unreliable. Images 404. Sites block you. Let's handle it:
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
except RequestException as e:
logger.warning(f"Failed to fetch {url}: {e}")
return None
4. Log Everything
When your crawler runs for 10 hours overnight, you want to know what happened:
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('data/tormes.log'),
logging.StreamHandler()
]
)
5. Respect the Web
This is the most important lesson. Your crawler shares the internet with everyone else.
- Check robots.txt
- Add delays between requests
- Use a descriptive User-Agent
- Don't hammer small sites
- Honor crawl-delay directives
Performance Expectations
Let's be real: Tormes is SLOW.
- 3 seconds between requests
- ~20 pages/minute
- 10,000 pages ≈ 8-10 hours
This is by design. If you want to crawl faster, you need to think about distributed systems, async I/O, politeness budgets per domain, etc.
This is for personal purposes so why not having it on the background while you sleep and see the results the next morning? I just did that and there were lots of surprises!
Future Prospect
It would be cool at some point to add the following:
- PageRank: Use the link graph to rank results
- Incremental crawling: Re-crawl pages that change
- Sitemap support: Seed from sitemap.xml files
- Distributed crawling: Multiple workers, shared queue
- JavaScript rendering: Use Selenium for dynamic sites
- Image search: Index images with computer vision
- Thumbnail generation: Create previews of archived pages
- Tokenizer: For fine-tuning LLMs with the indexed content
Resources
Some stuff I have used and have asked AI to search for so there can be a bit of bibliography:
Books:
- Introduction to Information Retrieval by Manning, Raghavan & Schütze
- Mining the Social Web by Matthew Russell
- Webbots, Spiders, and Screen Scrapers by Michael Schrenk
- Information Retrieval: Advanced Topics and Techniques by Association for Computing Machinery (edited by Omar Alonso and Ricardo Baeza-Yates)
Blog Posts
- Web Crawler System Design: https://www.enjoyalgorithms.com/blog/web-crawler
- Inverted Index: The Backbone of Modern Search Engines: https://satyadeepmaheshwari.medium.com/inverted-index-the-backbone-of-modern-search-engines-8bfd19a9ff75
- Inverted Index: https://blogs.30dayscoding.com/blogs/system-design/designing-data-intensive-applications/search-and-indexing/inverted-index/
- System Design of Google Search Engine: https://deepaksood619.github.io/computer-science/interview-question/system-design-google-search/
- What is full-text search and how does it work?: https://www.meilisearch.com/blog/how-full-text-search-engines-work
Libraries:
requests- HTTP for humansBeautifulSoup- HTML parsingWhoosh- Pure Python searchFastAPI- Modern Python web frameworkClick- CLI framework
Specs:
- robots.txt RFC: https://www.rfc-editor.org/rfc/rfc9309.html
- HTTP/1.1 spec: https://www.rfc-editor.org/rfc/rfc2616.html
Closing Thoughts
The end is near (maybe) so God bless Tormes! Self-hosting, DIY is the key to success in the future - and isn't there a better way to do this by having your own search engine? I think I had lots of fun while building this and there's still much left to do but overall the results are excellent and this is a good way to go.
I don't think there's nothing hard about algorithms themselves since they are solved problems). There's worse than that:
- Handling the chaos of real-world HTML
- Balancing speed vs. politeness
- Managing state across long crawls
- Debugging issues that only appear after 1000 pages
But at the end of the day it doesn't matter when you get the job done. Start simple. Get something working. Then iterate.
Happy crawling!